The basics of cache, cache coherency, and “false sharing”
Based on
- “What Every Programmer Should Know About Memory”, by U. Drepper,
- the cache memory lectures by Harry Porter (from Portland State University),
- and Scott Myers’ 2014 talk “Cpu Caches and Why You Care”.
In these videos, we’re going to talk about a cache-related slowdown phenomenon that can occur for parallell code called “false sharing”. False sharing may cause significant slowdowns while at a first glance being hard to detect. But if you remember how cache works, and use perf like a boss, “false sharing” ain’t got nothin’ on you.
Why cache?
Roughly speaking, there are two kinds of RAM. Static RAM (SRAM) and dynamic RAM (DRAM). DRAM is cheap, needs to continually refreshed, and is slower than SRAM, which is fast but expensive. Modern computers therefore have a RAM tradeoff – they use a small amount of SRAM close to the CPU, and a larger amount of DRAM connected to the CPU via a bus.
The most common way of using the precious SRAM is to store recently used data or instructions – to cache them. This turns out to be pretty effective, since programs often access the same area of memory repeatedly (spatial locality), and a lot of instructions are used repeatedly in rapid succession (temporal locality).
Cache hierarchy
Let us recall what Martin told us about hardware architecture in week 2. We recall that CPU caches are divided into levels.
The layout could be something like the following (if you want to know for sure, you should always take a look at your CPU datasheet):
- L1 cache – directly connected to an individual core. Often split into L1i (instruction cache) and L1d (data cache).
- L2 cache – shared between cores.
- L3 cache – shared between all cores.
In rare cases, there is also an L4 cache (such as for some processors in the Broadwell and Haswell architectures). Should you be in a spot where you have to code in such a way that you want to effectively utilize an L4 cache, you’re well beyond the scope of this course, and then I’ll leave to your own devices. I’ll also not talk so much about L1i, because frankly, I’m still learning about it.
For the visual learners among you, it might be beneficial to think of the above cache hierarchy in terms of the following picture:
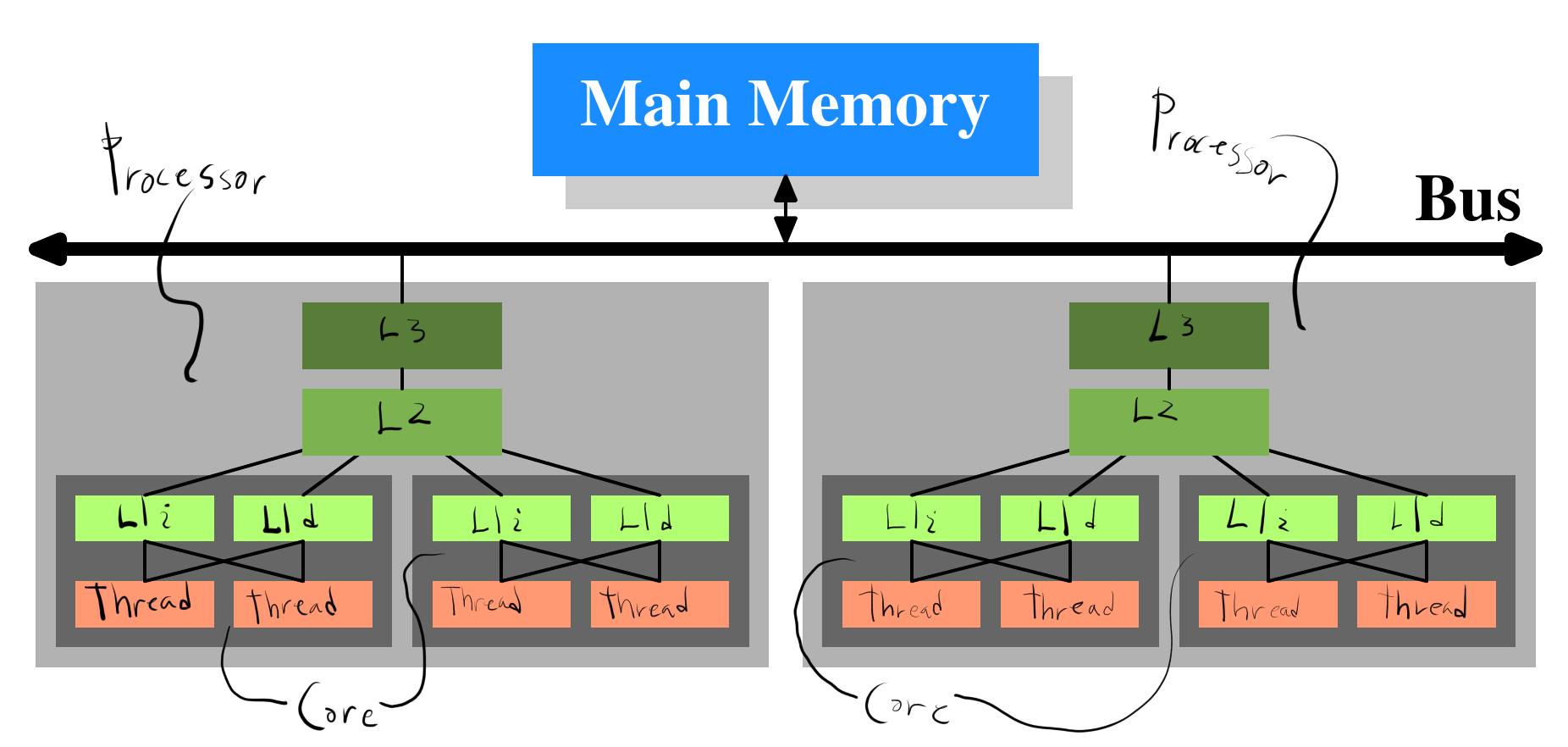
In this picture, we have two separate processors on the same bus. This is of course not typical for a desktop computer, but is the case for Gantenbein, which we recall from the output of lscpu is dual socket.
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 112
On-line CPU(s) list: 0-111
Thread(s) per core: 2
Core(s) per socket: 28
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8180 CPU @ 2.50GHz
Stepping: 4
CPU MHz: 1000.079
BogoMIPS: 5000.00
Virtualization: VT-x
L1d cache: 1.8 MiB
L1i cache: 1.8 MiB
L2 cache: 56 MiB
L3 cache: 77 MiB
[...]
However, on Gantenbein’s two Intel Xeon Platinum 8180, and on many modern Intel CPUs, only L3 is shared between all cores and the L1 and L2 caches are private (not shared).
Cache lines
We programmers are never in direct control of cache. Whenever the CPU reads or writes data, it’s going to store the data (and a neighborhood of it) in cache.1 All we can do is to place the data in a cache-friendly way.
Whenever the CPU needs some data in memory, it’s going to search through the cache by level for that data first (going from L1d, to L2, to L3). The way this is accomplished is that the address of the data is associated with a tag that the cache memory uses to locate the data in the cache. So, if the CPU wants to access data at address \(X\), it’ll first search through the cache for the tag associated to \(X\). Since the cache is small, this will be faster than reading from main memory, given of course that we find the data in the cache (in cache lingo – if we get a cache hit). If we don’t find a match (in cache lingo – a cache miss), then we use the tag to place the data (and a neighborhood of it), in the cache.2
Since it’s likely that we’ll use neighboring memory together3, and since main memory (to be more specific – DRAM) is faster when reading a lot of data in a row (because of capacitors and such), we don’t read just single bytes into cache. Rather, we read contiguous chunks of 64 bytes of main memory (in cache lingo, blocks) into cache.4 Cache is indexed in terms of these chunks, which henceforth are referred to by their proper name cache lines.
REMARK: It is common to refer to both the entries in the cache, and the corresponding chunks of 64 bytes in main memory as cache lines, and identify them with each other.
The following picture might help you remember:
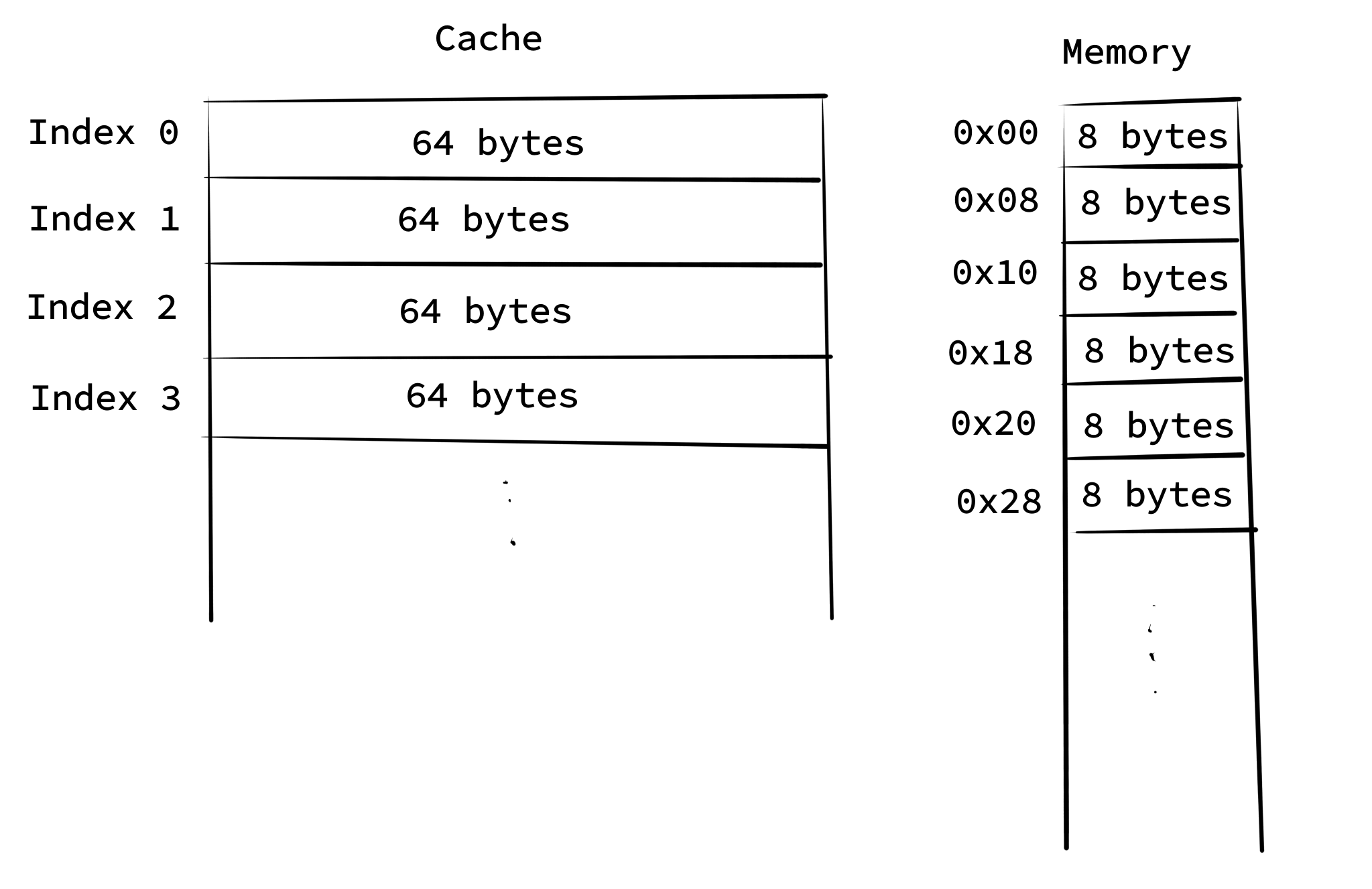
Keep in mind however that the above picture is just a heuristic. In reality, what your programs see are virtual memory addresses, which are mapped to physical addresses by the OS kernel and the CPU. All you need to understand as a (Linux) programmer is the concept of a process.
Now we get into a rather hairy area of caching – how to associate memory addresses to cache lines in a way that makes it fast to find data in cache, and to place data in cache.
Addresses to cache lines
In this section we’ll talk about fully associative caches, direct mapped caches, and set-associative caches. The former two are special cases of the latter.
Henceforth, let us consider memory addresses as being divided up to into 3 pieces, as in the following picture:
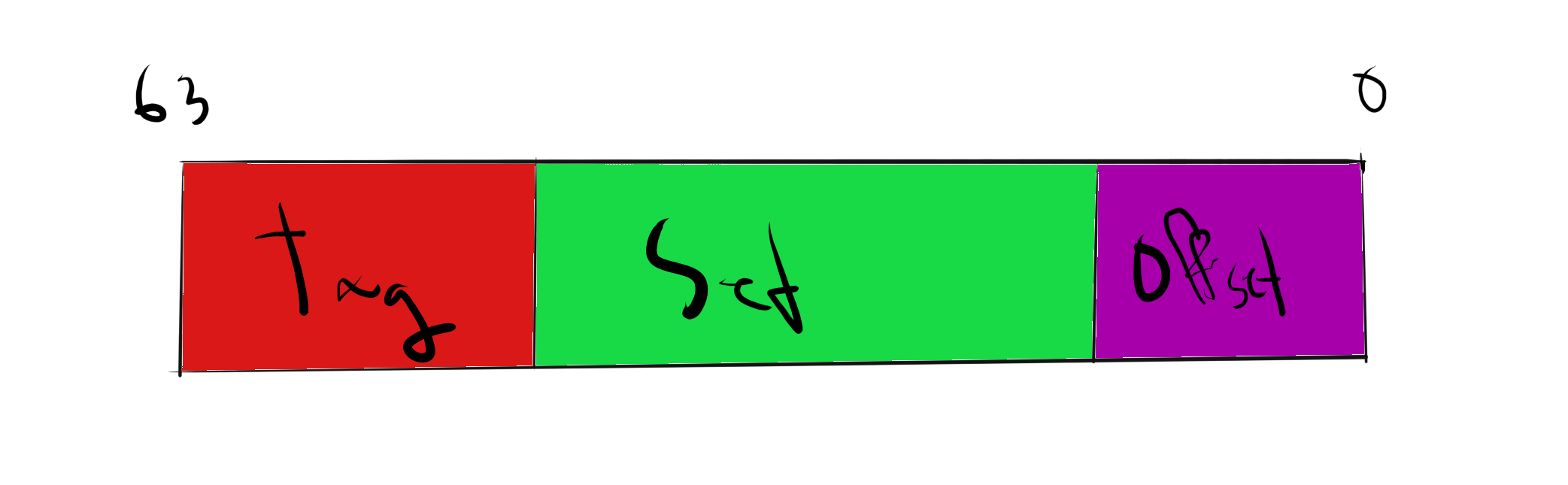
The number of tag bits and set bits will vary depending on the cache implementation. The number of offset bits will depend on the size of the cache line.
The tag, set, and offset bits, are used by the cache to look for a match. The tag and set bits are used to find (if it exists) a cache line that contains the (cached copy of the) byte the address is pointing to. The offset bits is used by the cache to select one of the bytes in cache line. So if we have a 64 byte cache line, we need \(\log_2(64)=6\) offset bits.
Fully associative caches
In a fully associative cache, we don’t use any set bits, so we only have to concern ourselves with the tag and the offset bits. Fully associative caches work a bit like “associative arrays” (also known as “maps” or “dictionaries”). The keys in the array are the tags, and the values are the cache lines. In addition to this, there is some logic to use the offset bits to select the appropriate byte in the cache line. Unlike the associative arrays you’ve encountered when programming, a fully associative array has a very limited amount of keys, and you can’t just add new keys at will. Instead, if there’s no match and you want to place data in cache, you have to decide to evict an already existing line. There are several different algorithms (cache replacement policies) to decide on which cache line to evict, e. g. least recently used, first in first out, last in first out, and so on. The interested reader is advised to consult this Wikipedia page. If it turns that the cache line that is going to be evicted has been modified (in cache lingo, it’s dirty), then it needs to be written back to memory first.
REMARK: It’s important to note however, that in a fully associative cache, there’s no hardware restriction on which cache line a main memory block is put into. This will not be the same for direct-mapped caches, as we shall soon see.
Here’s a way of thinking of it in Julia:
function match(cache::Dict{BitVector, Vector{Char}}, addr::BitVector)
tag = addr[7:64]
offset = addr[1:6]
cacheline = FAC(tag)
if !isnothing(cacheline)
return cacheline[Int(offset)]
else
#evict and replace
end
end
Let me draw a simple picture for you of some idealized matching logic of a fully associative cache with 4 lines and 64 bytes per line – a 256 byte cache.
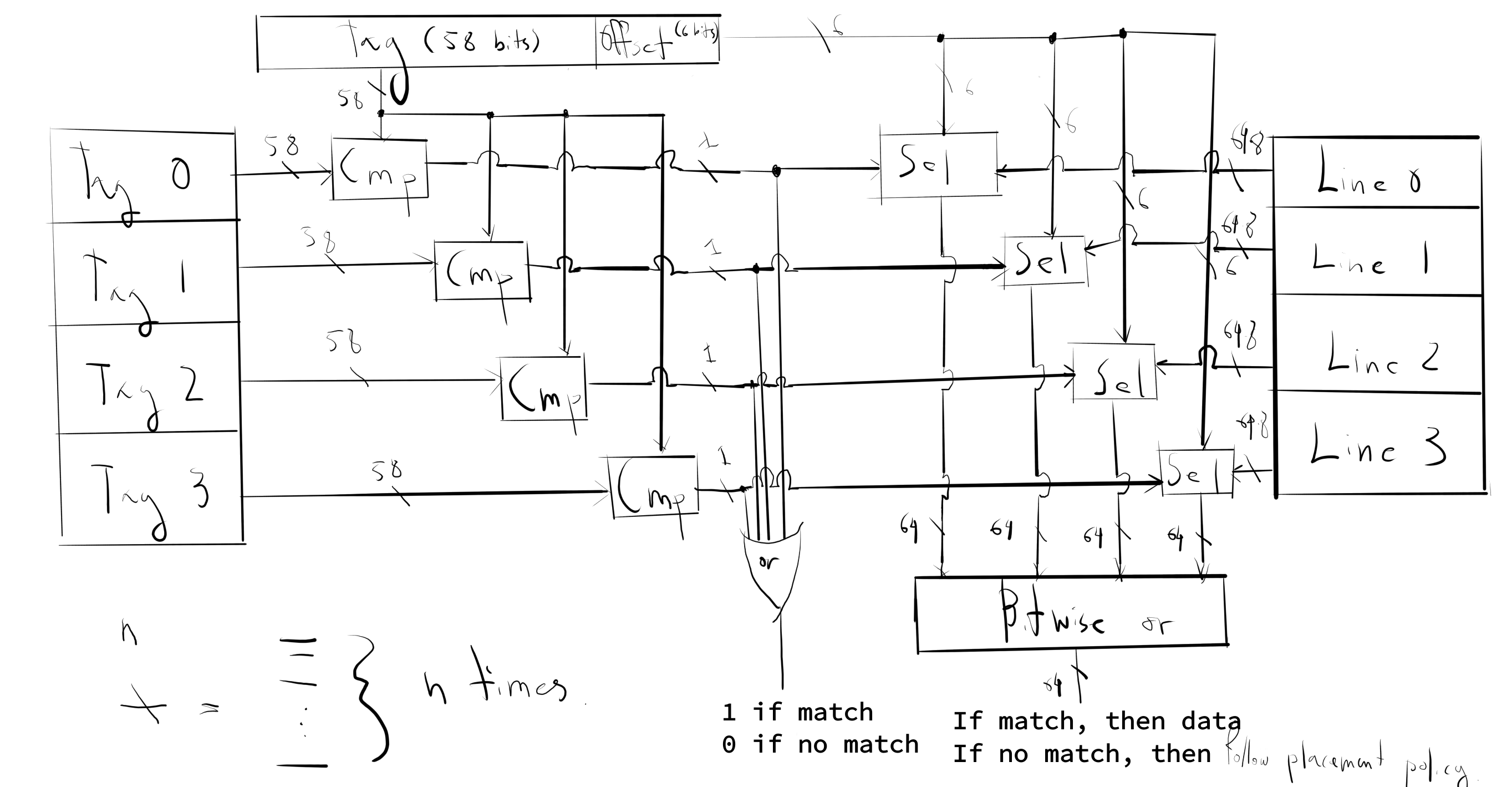
In this picture Cmp is a component that returns 1 if all bits match, otherwise it returns 0. The components Sel returns the byte indicated by the offset in the data coming from the right input if the left input is 1, otherwise it returns the byte 0x00.
Obviously, more logic is required to implement the (re)placement policy, but we’ll that for another course. If you can get a hold of some gates, it’d be an interesting Shannon-esque exercise.
Fully associative caches seem great in theory, but if you want to have a lot of cache lines, it’ll be pretty hard to implement in hardware. But for some special caches, like the translation lookaside buffer (TLB, used in conjunction with the translation between virtual addresses used by processes, to physical addresses), fully associative caches are used.
Direct mapped caches
In a direct-mapped cache, you are no longer free to put a main memory block in whichever cache line you want. Instead, this will be determined by the set bits. That’s right, for direct-mapped caches, we use all three of the tag, set, and offset fields. In a direct-mapped cache, we don’t have compare the tag bits of the address with a whole bunch of cache line tags, and this makes it easier to build than a fully associative cache (just use a multiplexer).
To see how we use the fields, let’s look at an example of a 512 line, 64 byte/line cache. (This time I’m not drawing out any circuitry, as I don’t think it helps particularly with the understanding.)
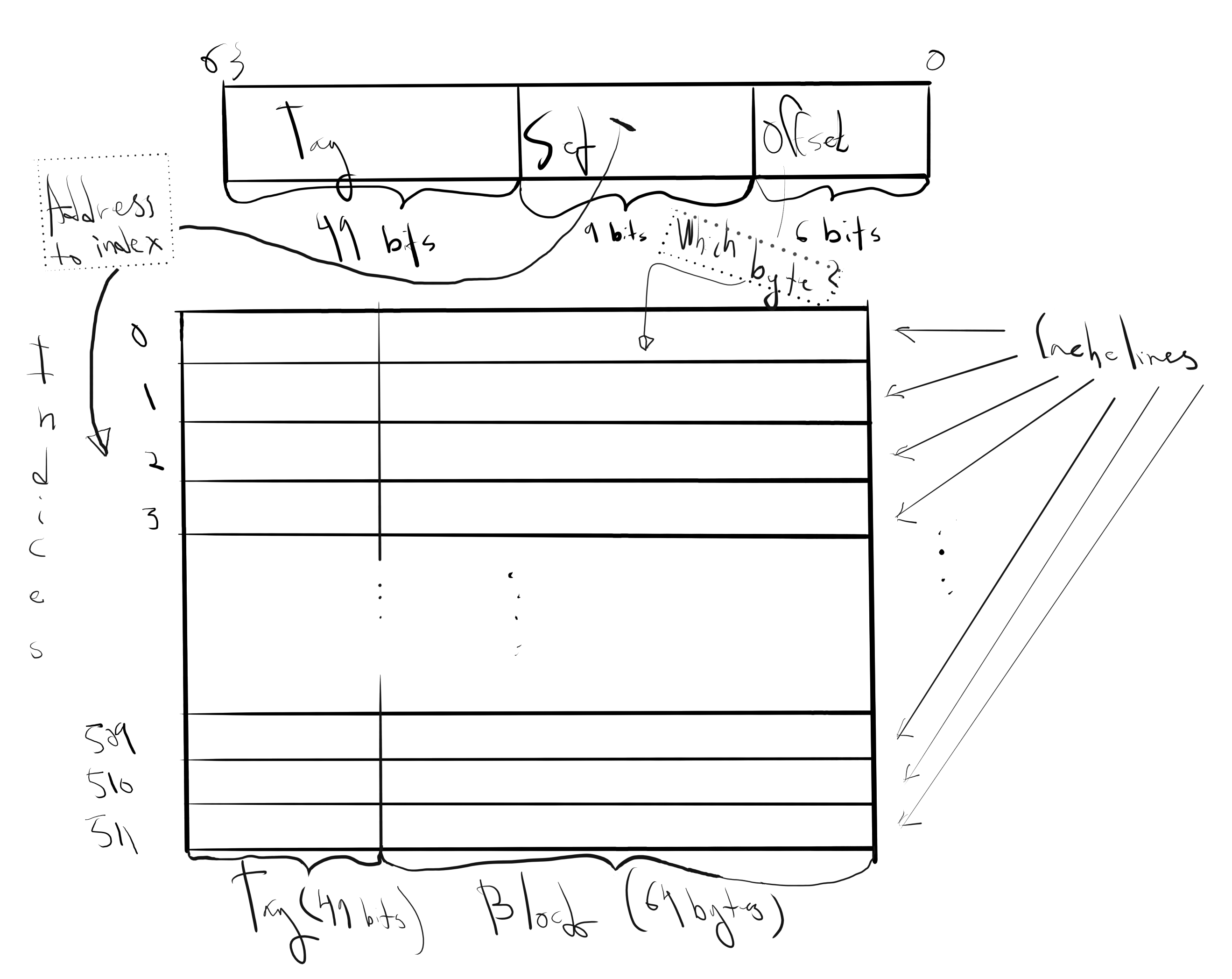
In the above example, when looking for a byte with address \(A\) in cache, we:
- Send in \(A\) to cache.
- Extract the set bits from \(A\).
- Use the set bits to select the associated cache line.
- Compare the tag bits of \(A\) with the tag on the cache line. If there’s match, we’ve a cache hit, and if there’s no match we’ve a cache miss. In the case of a miss, we proceed along the same lines as described in the previous section.
On a given cache line, say with set bits 0d123=0b001111011, the possible tags are
0b0000000000000000000000000000000000000000000000000
through to
0b1111111111111111111111111111111111111111111111111
Hence the possible starting addresses of the memory block stored in the cache line are
0b0000000000000000000000000000000000000000000000000 001111011 000000 = 0d7872– associated with the main memory block with starting address \(7872\) and ending address \(7935\).0b0000000000000000000000000000000000000000000000001 001111011 000000 = 0d40640– associated with the main memory block with starting address \(40640=7872+2^{15}\) and ending address \(40703\),0d73408- and so on.
There is a drawback with direct mapped caches. In the above example, it is possible (although unlikely) that our program needs to access data at for example the main memory addresses and 0d7872 and 0d40644 in close succession. This data belongs to blocks that will be cached on the same line, and therefore we need to repeatedly evict the cache line. This situation has a large hit on performance and is referred to as cache thrashing. (See also Harry Porter’s 6th video at 9:40.)
One way of avoiding issues such as cache thrashing is to use a compromise between fully associative, and direct-mapped caches: set-associative caches.
Set-associative caches
Set-associative caches work by dividing up the cache lines into sets, where each set of cache lines work like a fully associative cache.
I’ll draw you a picture again, and then I’ll explain how it works. The picture depicts a 32 kilobyte 8-way associative cache with 64 bytes per line.
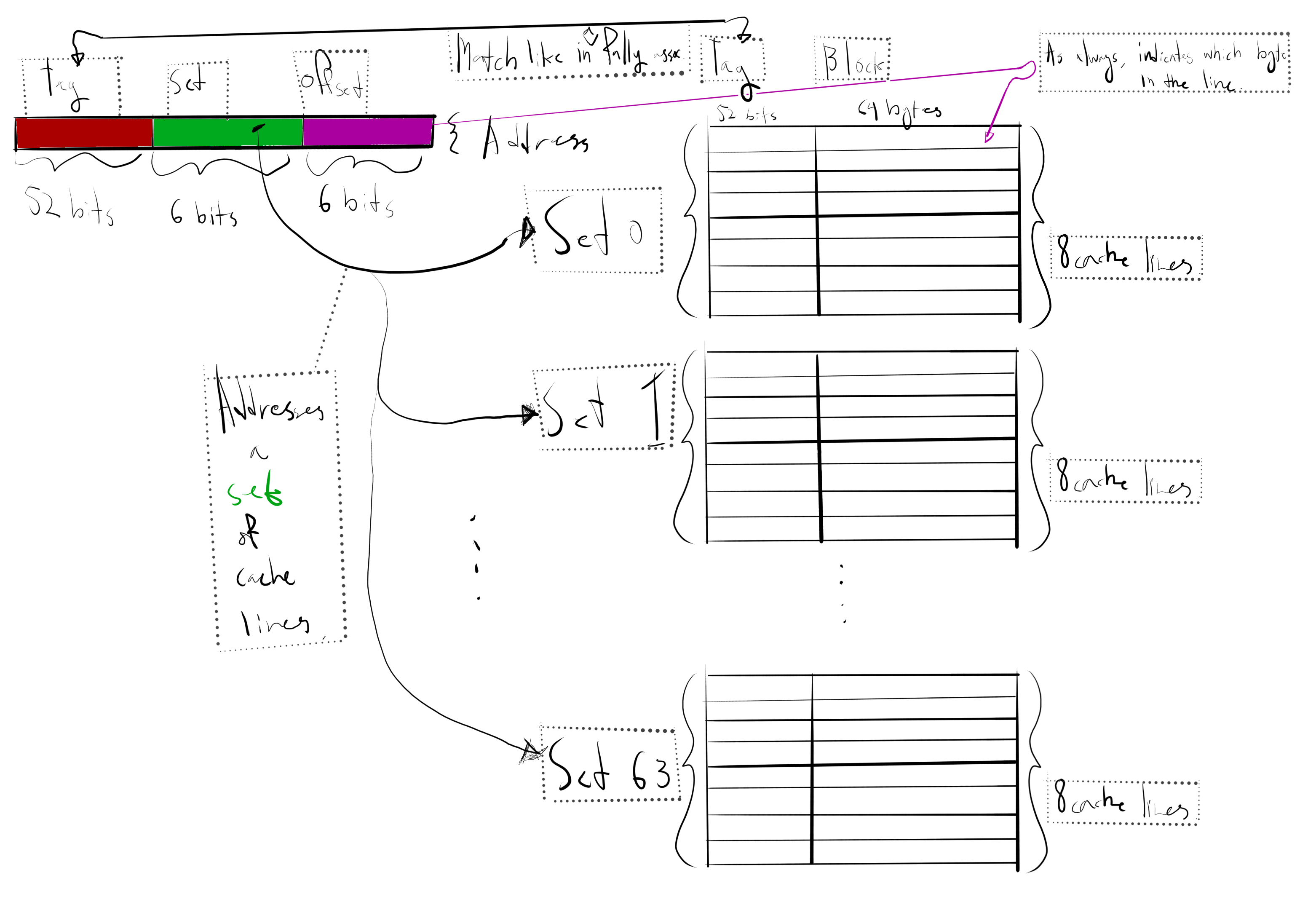
This cache is called 8-way because every cache set contains 8 cache lines, and we see that
$$8\cdot 64\cdot 64\text{ B}=32768\text{ B}=32\text{ kB}$$
so that indeed the total size of the cache is 32 kilobyte, as we claimed.
Let’s now describe how this cache works when looking for a byte with main memory address \(A\).
- Send in \(A\) to the cache.
- Extract the set bits from \(A\).
- Use the set bits to select the associated cache set.
- Compare the tag bits of \(A\) with the tags of the 8 cache lines in the set (like in a fully associative cache). If there’s a cache hit, you’re golden – read your desired byte from the cache line using the offset bits. If there’s a cache miss, follow the cache placement policy.
What’s neat about a set-associative cache is that the likelihood of thrashing your cache is significantly reduced. There’s no longer a single tag in the cache set (like with a direct mapped cache), and instead there are 8 (in our example).
Hence, we could store the bytes with addresses
\(A=\)
0b0000000000000000000000000000000000000000000000000000 010111 000001
and
\(B=\)
0b0000000000000000000000000000000000000000000000000010 010111 000011
in the same cache set (with index 0d23).
Concluding thoughts on cache layout
The above is only a very brief overview of cache layout, and there is far more to be learned if you want to really go far down the rabbit hole. However, for the purpose of understanding cache-related slowdown issues, it should be more than enough.
Cache coherency
Now we’re finally ready to talk about cache-related slowdowns in a multi-core setting. All cores should, in the words of Drepper, “see the same memory content at all times”. This is called cache coherency.
It is however inefficient for the cores to share the caches completely, and therefore they achieve coherency by communicating with each other using a well-established protocol. There are several different cache coherency protocols (MESI, MOESI, MESIF, to name a few), but we will focus on the MESI protocol because it gives us the necessary general picture.
In what follows, I will consider coherency between different cores but the ideas presented work also for threads. (For threads, a cache line on the same core needs keep track of separate cache line states for the different threads – I will not go into details on how that works, because I frankly haven’t learned that yet.)
The MESI protocol
REMARK: This section follows Drepper closely. Advanced (or wanting to be advanced) students might wish to just read Drepper.5
In the MESI protocol, a cache line can be in four different states (remember that we are in a multi-core setting):
- Modified – the cache line has been modified.
- Exclusive – the cache line is not modified, but is known to not be loaded into another core’s cache.
- Shared – the cache line is not modified, but could exist in another core’s cache.
- Invalid – the cache line is unused.
Let’s go through how a cache line changes through all these states using the following neato finite state machine.
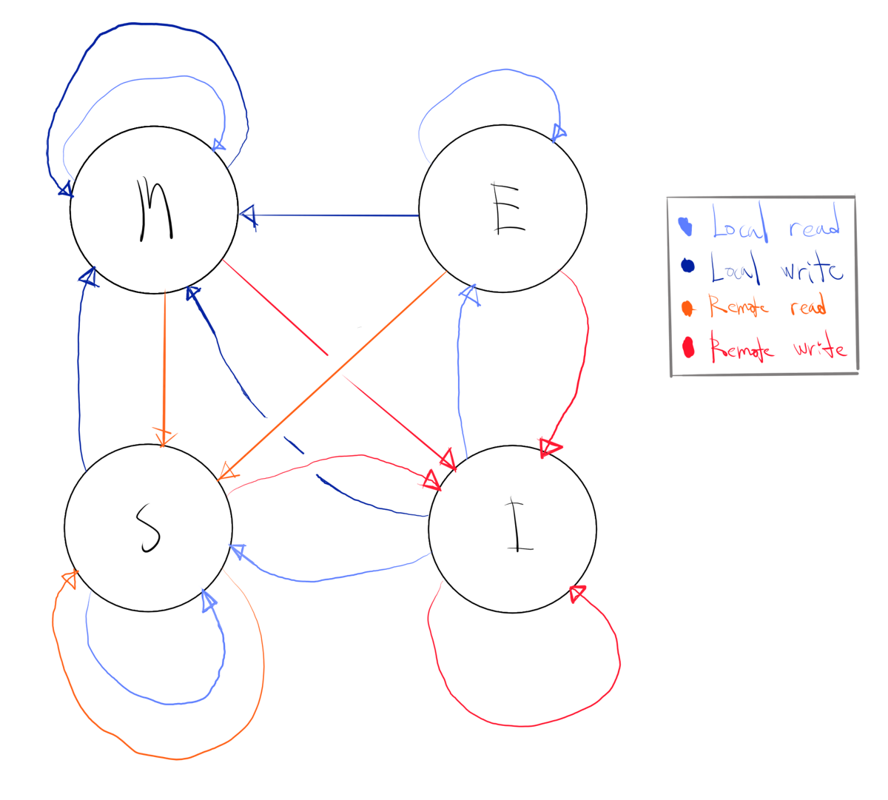
Let’s do a walkthrough:
Starting at invalid
In this case, we need to read from main memory, this is slow, but obviously is still a necessary first step.
- At the start, all caches are empty and thus marked as invalid.
- If data is loaded into a cache line for writing, it is set to modified.
- If data is loaded into a cache line for reading, there are two cases.
- If the data is present in a cache line belonging to some other core, the cache line is set to shared.
- If not, then the cache line is set to exclusive.
Starting at modified
- If a modified cache line is read from or written to by the local core, we can use the content and state remains modified.
- If a second core wants to read from a cache line marked as modified in the first core (in cache lingo, hit on a modified cache line, HITM), then the first core must send the cache line to the second core and mark the cache line as shared. The cache line also needs to go over the bus into the associated addresses in main memory (to ensure coherency).
- If a second core wants to write to a cache line marked as modified in the first core (HITM), then the first core sends over the cache line (as above, including sending the cache line to main memory) and marks it locally as invalid.
The communication needed in the latter two cases can lead to considerable slowdowns, and the slowdown that is caused by “false sharing”.
Starting at shared
- If a shared cache line is read from by the local core, it remains shared and the data is retrieved.
- If a shared cache line is written to by the local core, it is changed to modified. Other copies of the cache line in other cores are all marked as invalid.
- If a shared cache line is read from by a remote core, the cache line remains shared and nothing is done locally.
- If a shared cache line is to be written to by a remote core, the cache line is marked as invalid.
In the latter two cases, no communication is needed.
Starting at exclusive
This is almost the same as when you start on shared, but with one difference:
- If an exclusive cache line is written to by the local core, it is changed to modified, but this is not communicated to the other cores.
Obviously, having a cache line in the exclusive state is great, because no slowdown caused by communication can occur.
False sharing
Now we know (more than) enough to understand what “false sharing” is, and to avoid it by using our knowledge about how cache is implemented. Let’s start with an example. We haven’t coded in a while, so let’s bring out some good old pthreads.
#include<threads.h>
#include<stdio.h>
#include<stdlib.h>
typedef struct{
int x;
int y;
} packedint;
packedint a = {1, 0};
int sum_val = 0;
#define REPS 500
int summer(void *arg){
int s = 0;
for(size_t reps=0; reps < REPS; ++reps){
s=0;
for(size_t ix = 0; ix < 1000000; ++ix)
s += a.x;
}
printf("summer done.\n");
sum_val = s;
return 0;
}
int incrementer(void *arg){
for(size_t reps=0; reps < REPS; ++reps){
for(int ix = 0; ix < 1000000; ++ix)
++a.y;
}
printf("incrementer done.\n");
return 0;
}
int main(){
int ret;
thrd_t threads[2];
//creation
if(ret = thrd_create(threads, summer, NULL)){
printf("Error creating thread: %d\n", ret);
exit(1);
}
if(ret = thrd_create(threads+1, incrementer, NULL)){
printf("Error creating thread: %d\n", ret);
exit(1);
}
//joining
for(size_t t = 0; t < 2; ++t){
if(ret = thrd_join(threads[t], NULL)){
printf("Error joining thread: %d\n", ret);
exit(1);
}
}
printf("x=%d, y=%d, sum_val=%d\n", a.x, a.y, sum_val);
return 0;
}
and here’s the makefile
.PHONY : all
TARGETS = falsesharing
lIBS = -lpthread
CFLAGS = -g -O0 -std=c11
all : $(TARGETS)
falsesharing : falsesharing.c
gcc $(CFLAGS) -o $@ $^ $(lIBS)
clean :
rm -f $(TARGETS)
We use GDB to debug this program. Let’s start to see at which address the struct resides, and where consequently we have the ints x and y.
(gdb) layout src
(gdb) b main
(gdb) r
(gdb) p &(a.x)
(gdb) p &(a.y)
Ok, so we see that a.x is at 0x404048 (when I was running it last time) and that a.y is at 0x40404c, i. e. 4 bytes away from a.x – as expected.6 Using x we can also examine the memory manually:
(gdb) x/8tb &a
Let’s convert the addresses to binary to see what the tag, set, and offset bits are.
0x404048 = 0b0...010000000100000001 0010000x40404c = 0b0...010000000100000001 001100
Since all bits except the offset bits are identical, a.x and a.y are in the same cache line – the one beginning on 0x404040. Before going in to the theory about what happens when we execute our code, let’s use a feature from perf called “cache-2-cache”, or “c2c” for short.
REMARK: Running
perfin this mode seems to require more than user rights, so I’m running it locally on my Intel Core i7-4700HQ.
Now we run in the command line
$ sudo perf c2c record ./example1
$ sudo perf c2c report --stdio > perf_report.txt
$ nvim perf_report.txt
The lines are long, so you might want to run set nowrap in the Vim console. The output you’ll get is something like:
=================================================
Trace Event Information
=================================================
Total records : 484479
Locked Load/Store Operations : 0
Load Operations : 239401
Loads - uncacheable : 0
Loads - IO : 0
Loads - Miss : 0
Loads - no mapping : 0
Load Fill Buffer Hit : 61937
Load L1D hit : 177457
Load L2D hit : 3
Load LLC hit : 2
Load Local HITM : 2
Load Remote HITM : 0
Load Remote HIT : 0
Load Local DRAM : 2
Load Remote DRAM : 0
Load MESI State Exclusive : 2
Load MESI State Shared : 0
Load LLC Misses : 2
LLC Misses to Local DRAM : 100.0%
LLC Misses to Remote DRAM : 0.0%
LLC Misses to Remote cache (HIT) : 0.0%
LLC Misses to Remote cache (HITM) : 0.0%
Store Operations : 245078
Store - uncacheable : 0
Store - no mapping : 0
Store L1D Hit : 235578
Store L1D Miss : 9500
No Page Map Rejects : 0
Unable to parse data source : 0
=================================================
Global Shared Cache Line Event Information
=================================================
Total Shared Cache Lines : 1
Load HITs on shared lines : 87137
Fill Buffer Hits on shared lines : 61934
L1D hits on shared lines : 25198
L2D hits on shared lines : 3
LLC hits on shared lines : 2
Locked Access on shared lines : 0
Store HITs on shared lines : 104713
Store L1D hits on shared lines : 95214
Total Merged records : 104715
=================================================
c2c details
=================================================
Events : cpu/mem-loads,ldlat=30/P
: cpu/mem-stores/P
Cachelines sort on : Total HITMs
Cacheline data grouping : offset,iaddr
=================================================
Shared Data Cache Line Table
=================================================
#
# ----------- Cacheline ---------- Total Tot ----- LLC Load Hitm ----- ---- Store Reference ---- --- Load Dram ---- LLC Total ----- Core Load Hit ----- -- LLC Load Hit --
# Index Address Node PA cnt records Hitm Total Lcl Rmt Total L1Hit L1Miss Lcl Rmt Ld Miss Loads FB L1 L2 Llc Rmt
# ..... .................. .... ...... ....... ....... ....... ....... ....... ....... ....... ....... ........ ........ ....... ....... ....... ....... ....... ........ ........
#
0 0x404040 0 98718 191850 100.00% 2 2 0 104713 95214 9499 0 0 0 87137 61934 25198 3 0 0
=================================================
Shared Cache Line Distribution Pareto
=================================================
#
# ----- HITM ----- -- Store Refs -- --------- Data address --------- ---------- cycles ---------- Total cpu Shared
# Num Rmt Lcl L1 Hit L1 Miss Offset Node PA cnt Code address rmt hitm lcl hitm load records cnt Symbol Object Source:Line Node
# ..... ....... ....... ....... ....... .................. .... ...... .................. ........ ........ ........ ....... ........ ............... ........ ............. ....
#
-------------------------------------------------------------
0 0 2 95214 9499 0x404040
-------------------------------------------------------------
0.00% 100.00% 0.00% 0.00% 0x10 0 1 0x4011b4 0 98 52 52422 1 [.] summer example1 example1.c:20 0
0.00% 0.00% 100.00% 100.00% 0x14 0 1 0x401227 0 0 0 104713 1 [.] incrementer example1 example1.c:31 0
In this report we see a bunch of mentions of HITM. We know that this leads to slowdowns, because the cache line has to be sent to memory and in addition be marked as invalid locally, which also will lead to cache misses later in the execution. This phenomenon is exactly what we call “false sharing”.
Let’s explain this using the MESI protocol and our knowledge of cache layout. Let’s for convenience call the thread that is running summer \(A\), and the thread that is running incrementer \(B\). We assume, without loss of generality, that \(A\) accesses a.x before \(B\) accesses a.y. What happens is then:
| \(A\) (reader) | \(B\) (writer) | Event |
|---|---|---|
| I | I | |
| E | I | \(A\) read (read over bus) |
| I | M | \(B\) wrote |
| S | S | \(A\) read (HITM, comm. over bus) |
| I | M | \(B\) wrote (false sharing) |
| S | S | \(A\) read (HITM comm. over bus) |
and so on. We see that when \(A\) read after \(B\) wrote, there’s a HITM, and an associated slowdown, and the cache line 0x404040 in both threads are marked as shared, but immediately afterwards, \(B\) writes again, which invalidates the shared state – the cache line was falsely shared.
How do we fix it?
At a high level the resolution to our issue is simple – make sure that the cache line isn’t shared. That is, make sure that we don’t get a HITM. Since \(A\) doesn’t rely on a modified version of a.y there’s no reason that we should load a.x from memory (or cache) over and over. We could instead store in a local variable. The same goes for a.y. Hence we could instead write the following program:
void *summer(void *arg){
int s = 0;
int temp = a.x;
for(size_t reps=0; reps < REPS; ++reps){
s=0;
for(size_t ix = 0; ix < 1000000; ++ix)
s += temp;
}
printf("summer done.\n");
sum_val = s;
return NULL;
}
void *incrementer(void *arg){
int temp = a.y;
for(size_t reps=0; reps < REPS; ++reps){
for(int ix = 0; ix < 1000000; ++ix)
++temp;
}
a.y = temp;
printf("incrementer done.\n");
return NULL;
}
Since the variables temp will be local on the threads, it is very unlikely that they’ll be in the same cache line. This is verified by running perf as before.
Another fix is to simple force a.x and a.y onto different cache lines, by using our knowledge of the fact that we’re using 64 byte cache lines. We could then simply pad the struct with extra bytes, like this:
typedef struct{
int x;
char pad1[60];
int y;
char pad2[60];
} packedint;
This is a much more portable solution, but has the drawback of requiring more memory. Once again, perf verifies that this fix also works.
-
As Drepper mentions, there are some places in memory that cannot be cached, but that’s something for the OS-people. ↩︎
-
As you’ll see later, this is a heavily simplified picture, and is only really true for fully associative caches. ↩︎
-
This is a bit of a “chicken or the egg” kind of situation. As programmers we learn that cache bets on spatial locality, and therefore we try to use contiguous blocks of memory, by choice. But CPU developers assume that our code uses memory contiguously and therefore design the CPUs to take advantage of this. Regardless, contiguous \(\Leftrightarrow\) good. ↩︎
-
On a 64-bit system, we can read 8 bytes (the word size) over the memory bus, and hence, filling up a cache line requires 8 transfers over the bus. ↩︎
-
If Laplace was a Unix-beard, he might’ve said “Lisez Drepper, lisez Drepper, c’est notre maître à tous.” instead. ↩︎
-
Had we used a struct with total size that isn’t a multiple of a power of two, say 5 bytes (an
intand achar), the compiler would pack the struct with extra space so that it becomes a multiple of a power of two. The reason for this is that the (our) CPU only reads in 8 byte chunks. ↩︎
{kind=link}